Input data
The hidecan package takes as input tibbles (data-frames)
of QTL mapping, GWAS and DE results or candidate genes. The input
data-frames should contain some mandatory columns, depending on the type
of data. Note that for each type of results, the full list of tested
regions/markers/genes should be passed to hidecan, not only
the significant ones; the package will take care of selecting the
significant results based on user-defined thresholds.
A list of example input datasets can be obtained via the
get_example_data() function:
x <- get_example_data()
str(x, max.level = 1)
#> List of 4
#> $ QTL : tibble [7 × 6] (S3: tbl_df/tbl/data.frame)
#> $ GWAS: tibble [35,481 × 4] (S3: tbl_df/tbl/data.frame)
#> $ DE : tibble [10,671 × 7] (S3: tbl_df/tbl/data.frame)
#> $ CAN : tibble [32 × 6] (S3: tbl_df/tbl/data.frame)QTL mapping results
QTL mapping results should be provided as a tibble or data-frame, with one row per QTL region. The data-frame should contain at least the following columns:
chromosome: character column, giving the ID of the chromosome on which each region is located;startandend: numeric columns, giving the starting and end position of the region along the chromosome (in bp);either
scoreorpadj: numeric column, providing either the score (i.e.-log10(p-value)) or the adjusted p-value of the region If ascorecolumn is provided, thepadjcolumn will be ignored. If only apadjcolumn is provided, ascorecolumn will be constructed as-log10(padj). Note that this column could be used to represent the estimated effect of the region, for example.
Any other column present in the data-frame will be ignored. An example of valid input is shown below:
head(x[["QTL"]])
#> # A tibble: 6 × 6
#> id chromosome start end score name
#> <chr> <chr> <dbl> <dbl> <dbl> <chr>
#> 1 qtl_1 ST4.03ch01 5600000 11300000 4.1 QTL 1
#> 2 qtl_2 ST4.03ch01 9500000 14000000 5.5 QTL 2
#> 3 qtl_3 ST4.03ch04 12700000 17600000 4.3 QTL 3
#> 4 qtl_4 ST4.03ch05 37600000 39900000 3.2 QTL 4
#> 5 qtl_5 ST4.03ch07 49900000 51700000 5.1 QTL 5
#> 6 qtl_6 ST4.03ch08 45000000 47000000 5.8 QTL 6GWAS results
GWAS results should be provided as a tibble or data-frame, with one row per genetic marker. The data-frame should contain at least the following columns:
chromosome: character column, giving the ID of the chromosome on which each marker is located;position: numeric column, the physical position along the chromosome (in base pairs - bp) of the marker;either
scoreorpadj: numeric column, providing either the score (i.e.-log10(p-value)) or the adjusted p-value of the region. If ascorecolumn is provided, thepadjcolumn will be ignored. If only apadjcolumn is provided, ascorecolumn will be constructed as-log10(padj).
Any other column present in the data-frame will be ignored. An example of valid input is shown below:
head(x[["GWAS"]])
#> # A tibble: 6 × 4
#> id chromosome position score
#> <chr> <chr> <dbl> <dbl>
#> 1 ST4.03ch00_45467783 ST4.03ch00 45467783 0.191
#> 2 ST4.03ch01_88589716 ST4.03ch01 88589716 1.84
#> 3 ST4.03ch02_48614228 ST4.03ch02 48614228 0.381
#> 4 ST4.03ch03_62263578 ST4.03ch03 62263578 0.661
#> 5 ST4.03ch04_72139135 ST4.03ch04 72139135 0.640
#> 6 ST4.03ch05_52040302 ST4.03ch05 52040302 0.346Differential expression results
DE results should be provided as a tibble or data-frame, with one row per gene. The data-frame should contain at least the following columns:
chromosome: character column, giving the ID of the chromosome on which each gene is located;startandend: numeric columns, giving the starting and end position of the gene along the chromosome (in bp). These two columns will be used to calculate the position of the gene as the half-way point between the start and end of the gene.either
scoreorpadj: numeric column, providing either the score (i.e.-log10(p-value)) or the adjusted p-value of the gene. If ascorecolumn is provided, thepadjcolumn will be ignored. If only apadjcolumn is provided, ascorecolumn will be constructed as-log10(padj).either
foldChangeorlog2FoldChange: numeric column, giving either the fold-change or log2(fold-change) of the gene. If alog2FoldChangecolumn is provided, thefoldChangecolumn will be ignored. If only afoldChangecolumn is provided, alog2FoldChangewill be constructed aslog2(foldChange).
Any other column present in the data-frame will be ignored. An example of valid input is shown below:
head(x[["DE"]])
#> # A tibble: 6 × 7
#> gene chromosome padj log2FoldChange start end label
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 PGSC0003DMG400032056 ST4.03ch00 0.787 0.0114 45813195 45813526 Prote…
#> 2 PGSC0003DMG400018039 ST4.03ch01 0.630 0.00529 88623473 88627702 PhD-f…
#> 3 PGSC0003DMG400020231 ST4.03ch02 0.864 0.00362 48563271 48578978 Acety…
#> 4 PGSC0003DMG400009197 ST4.03ch03 0.530 0.0320 62256322 62258929 Phosp…
#> 5 PGSC0003DMG403025662 ST4.03ch04 0.975 0.00225 72168842 72170119 Conse…
#> 6 PGSC0003DMG400023316 ST4.03ch05 NA -0.000726 52039916 52040326 Conse…(Note that in the example dataset, some genes have missing values in
the padj column; this corresponds to genes that have been
filtered out via independent
filtering in the DESeq2 package).
Candidate genes
A list of candidate genes (e.g. genes previously found associated with a trait of interest based on literature search) can be provided as a tibble or data-frame, with one row per gene. This data-frame can also contain variants of interest (see below). The data-frame should contain at least the following columns:
chromosome: character column, giving the ID of the chromosome on which each gene is located;startandend: numeric columns, giving the starting and end position of the gene along the chromosome (in bp). These two columns will be used to calculate the position of the gene as the half-way point between the start and end of the gene. For genomic variants or markers, simply set both thestartandendcolumns to the physical position of the marker.name: character column, giving the name of the candidate gene that will be displayed in the HIDECAN plot. Set toNAfor any subset of genes to remove their label in the plot (can help if many genes are very close, to avoid cluttering the plot).
Any other column present in the data-frame will be ignored. An example of valid input is shown below:
head(x[["CAN"]])
#> # A tibble: 6 × 6
#> id chromosome start end name gene_name
#> <chr> <chr> <dbl> <dbl> <chr> <chr>
#> 1 PGSC0003DMG400003155 ST4.03ch03 46757152 46762127 4CL 4-coumarate-CoA …
#> 2 PGSC0003DMG400014223 ST4.03ch03 57466692 57469946 4CL2 4-coumarate-CoA …
#> 3 PGSC0003DMG400011189 ST4.03ch07 1001854 1006278 HQT HQT
#> 4 PGSC0003DMG400005492 ST4.03ch05 36342746 36347409 PAL phenylalanine am…
#> 5 PGSC0003DMG400005279 ST4.03ch05 42523943 42525912 peroxidase peroxidase
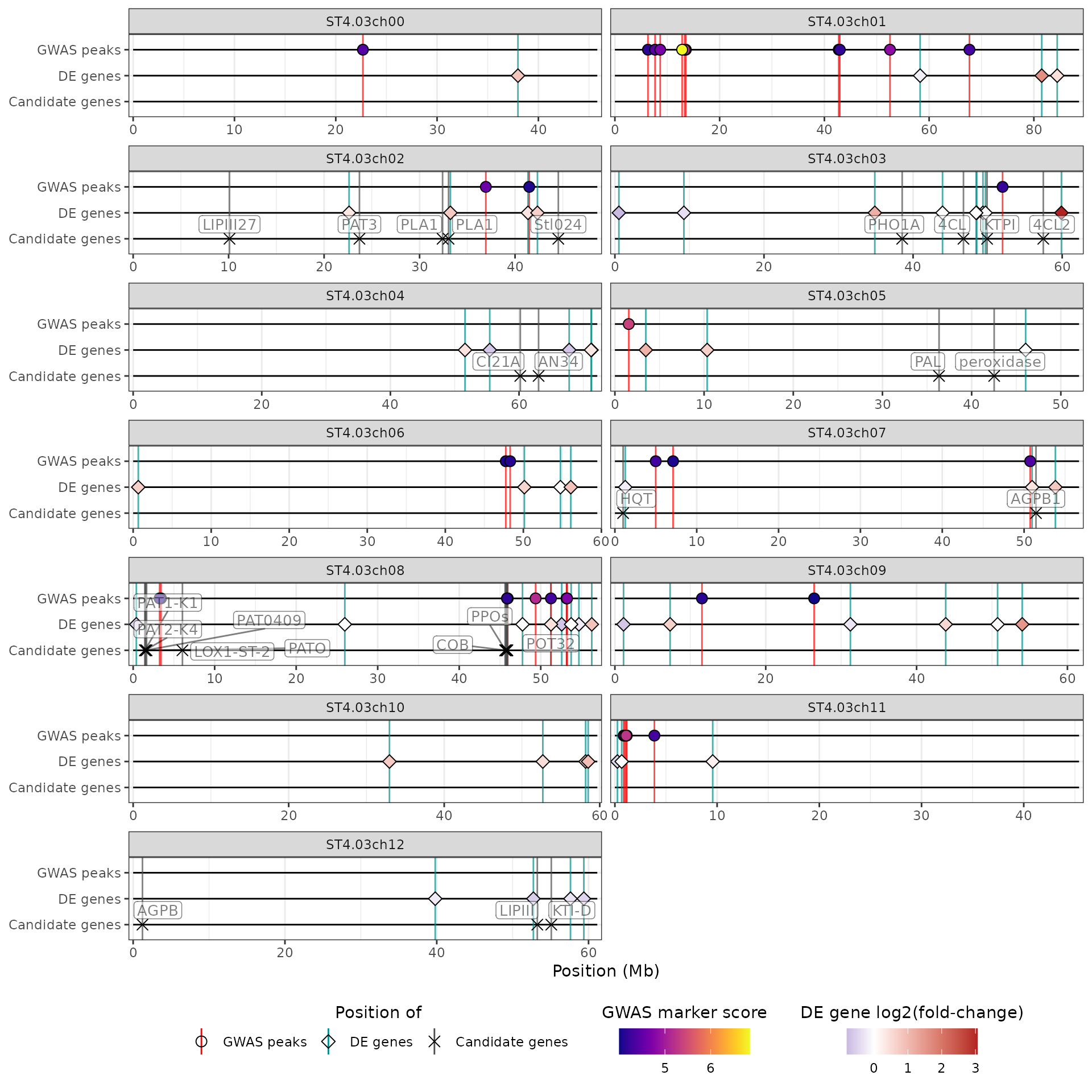
#> 6 PGSC0003DMG400007782 ST4.03ch03 38537202 38540209 PHO1A PHO1ACreating a HIDECAN plot
The hidecan_plot() function creates a HIDECAN plot. It
takes as input the data-frames presented above, as well as the score and
log2(fold-change) thresholds used to select the significant markers and
genes.
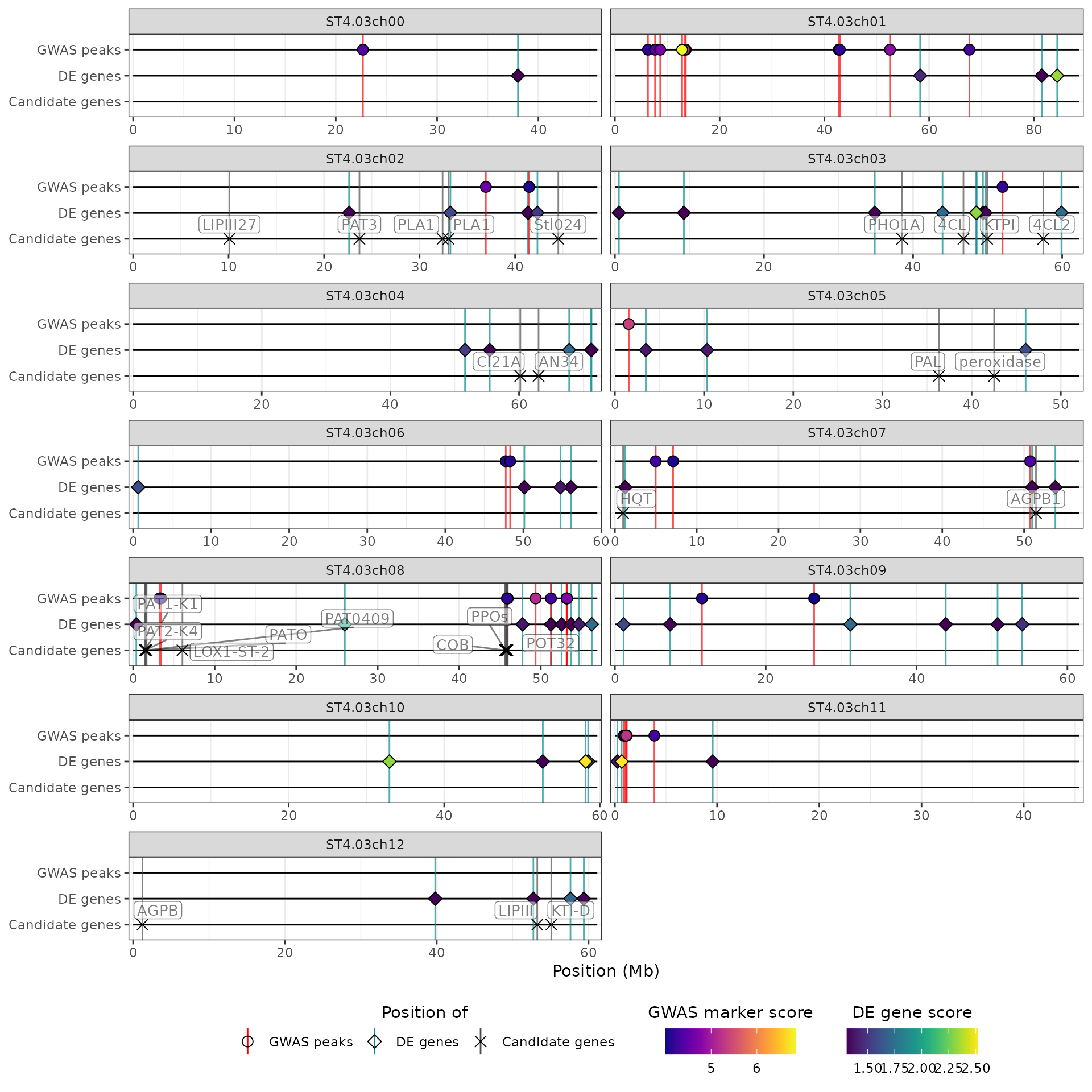
In this example, we only show QTL regions and markers with a score above 4, which corresponds to a p-value below , and genes with a score above 1.3, which corresponds to a p-value of 0.05. We don’t place any threshold on the log2(fold-change) of the genes:
hidecan_plot(
qtl_list = x[["QTL"]], ## data-frame of GWAS results
gwas_list = x[["GWAS"]], ## data-frame of GWAS results
de_list = x[["DE"]], ## data-frame of DE results
can_list = x[["CAN"]], ## data-frame of candidate genes
score_thr_qtl = -log10(0.0001), ## sign. threshold for QTL
score_thr_gwas = -log10(0.0001), ## sign. threshold for GWAS
score_thr_de = -log10(0.05), ## sign. threshold for DE
log2fc_thr = 0 ## log2FC threshold for DE
)
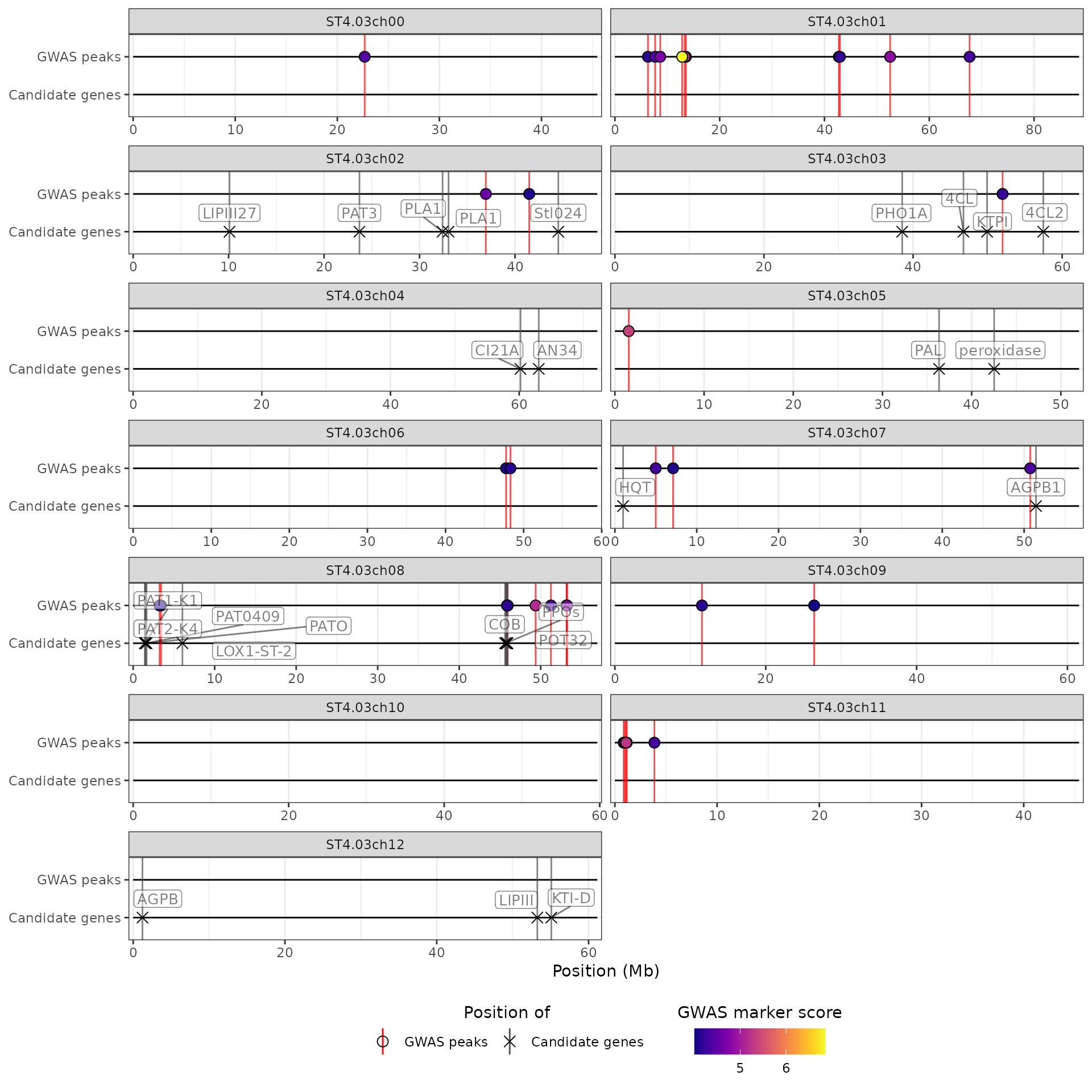
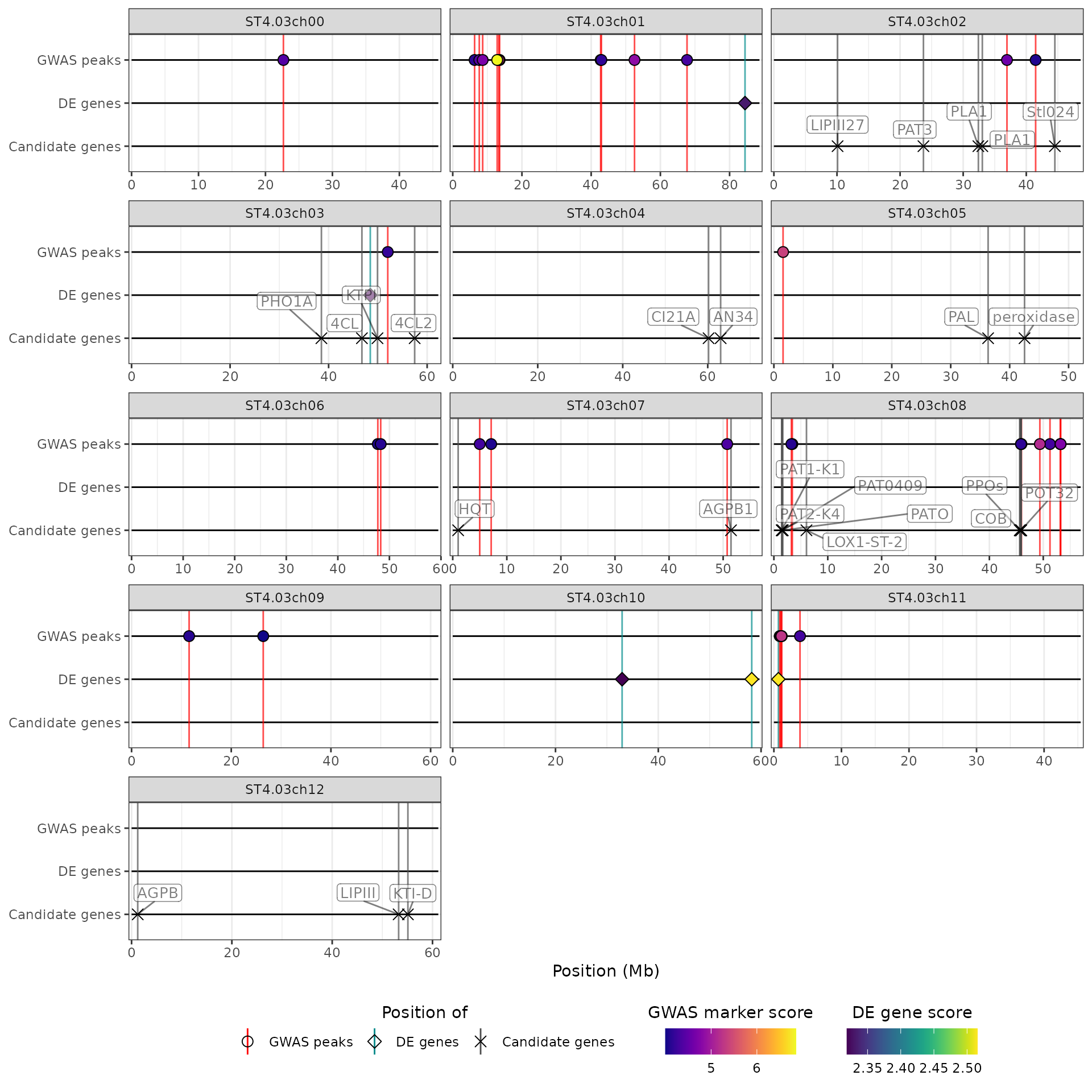
Note that it is possible to provide only a subset of the possible input data, e.g. only GWAS results and a list of candidate genes:
hidecan_plot(
gwas_list = x[["GWAS"]],
can_list = x[["CAN"]],
score_thr_gwas = 4
)
Removing empty chromosomes
By default, the HIDECAN plot shows all chromosomes present in the
input data. However, it is possible that some of the chromosomes appear
empty, as they do not contain any significant region, marker or gene,
nor any candidate gene. In this case, it is possible to exclude such
“empty” chromosomes from the HIDECAN plot, through the
remove_empty_chrom argument.
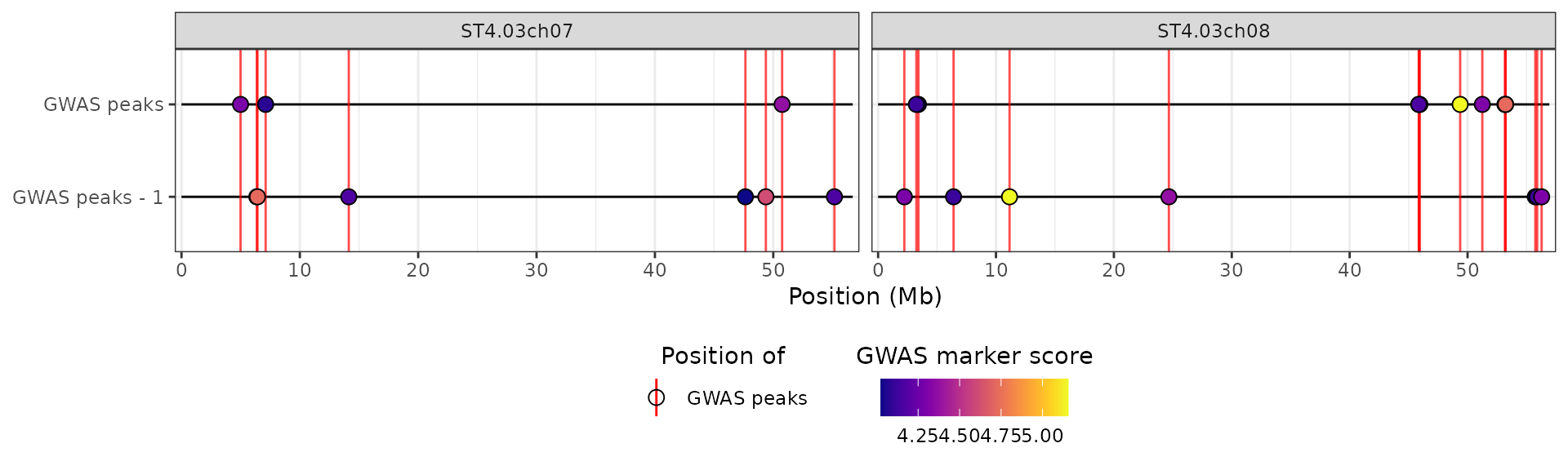
We will demonstrate that by increasing the score threshold applied to the GWAS results, in order to get fewer significant markers. In this case, chromosomes 0, 6, 9 and 10 do not contain any significant marker of gene of interest:
## Chromosomes 0, 6, 9 and 10 are empty
hidecan_plot(
gwas_list = x[["GWAS"]],
can_list = x[["CAN"]],
score_thr_gwas = 5
)![]()
By setting the remove_empty_chrom argument to
TRUE, these chromosomes will be removed from the plot:
hidecan_plot(
gwas_list = x[["GWAS"]],
can_list = x[["CAN"]],
score_thr_gwas = 5,
remove_empty_chrom = TRUE
)![]()
Selecting chromosomes and genomic positions
It is possible to specify which chromosomes should be represented in
the HIDECAN plot, via the chroms argument. For example,
with the following command we restrict the plot to chromosomes 7 and
8:
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
chroms = c("ST4.03ch07", "ST4.03ch08")
)
We can also “zoom in” on some or all chromosomes, through the
chrom_limits argument. To zoom in on all chromosomes at
once, we pass to the chrom_limits argument an integer
vector of length 2, which gives the lower and upper limits in bp to use.
In that case, the QTL regions will be cropped to these limits as well.
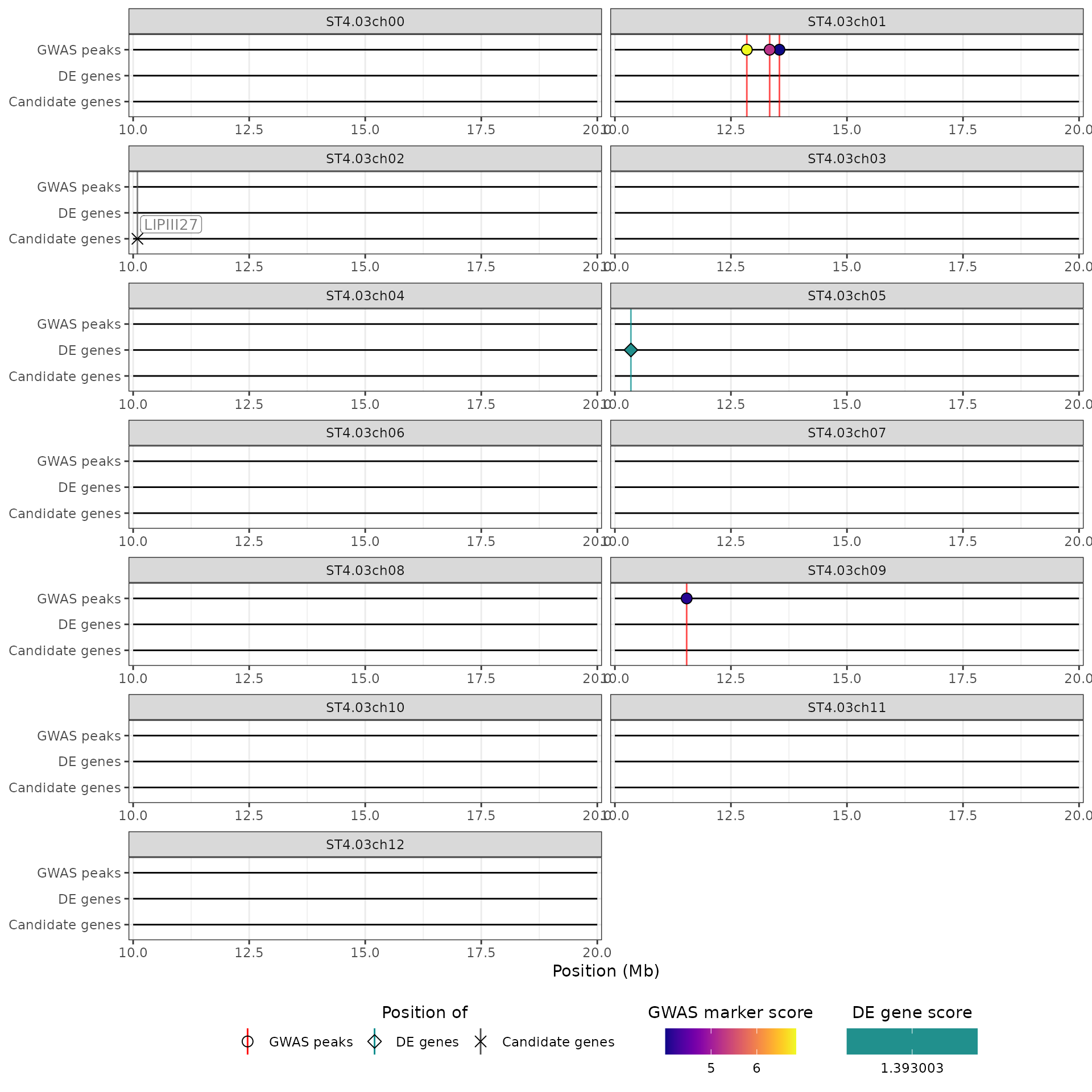
For example here, we focus on the 10-20Mb region of each chromosome:
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
chrom_limits = c(10e6, 20e6)
)
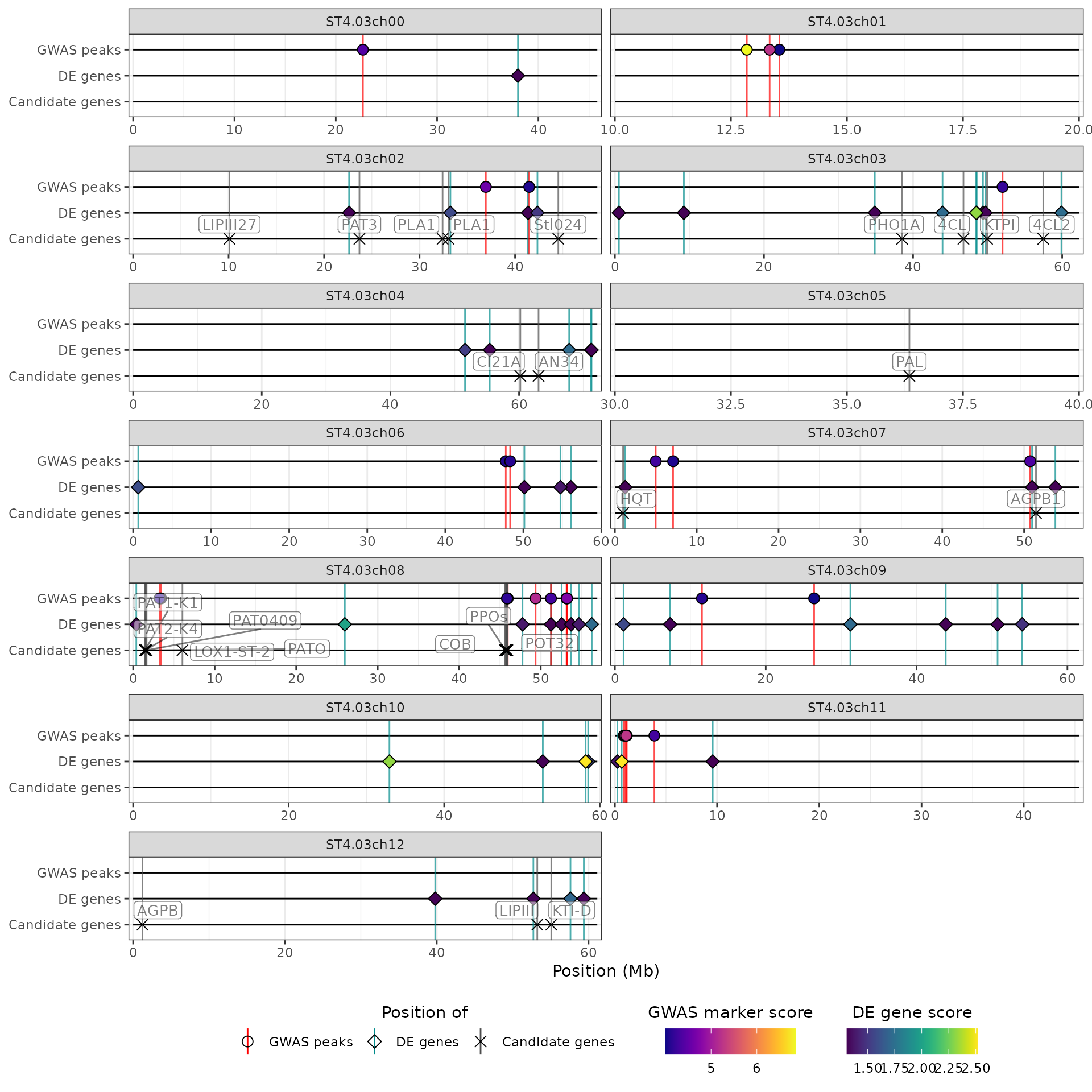
Alternatively, we can apply different limits to some of the chromosomes, by passing a named list to the argument. The names of the list should match the chromosomes name, and each element should be an integer vector of length 2 giving the lower and upper limits in bp to use for the corresponding chromosome. For example, we will focus on the 10-20Mb region for chromosome 1, and the 30-40Mb region for chromosome 5, and leave all other chromosomes as is:
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
chrom_limits = list("ST4.03ch01" = c(10e6, 20e6),
"ST4.03ch05" = c(30e6, 40e6))
)
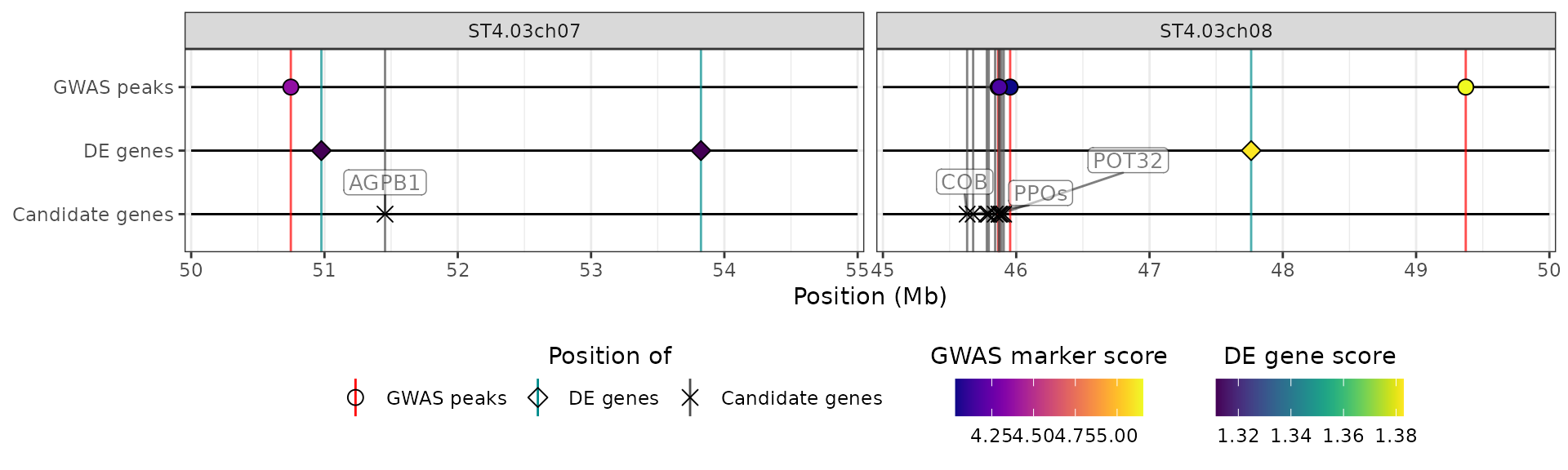
The two options chroms and chrom_limits can
be used together:
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
chroms = c("ST4.03ch07", "ST4.03ch08"),
chrom_limits = list("ST4.03ch07" = c(50e6, 55e6),
"ST4.03ch08" = c(45e6, 50e6))
)
Colour genes by log2(fold-change)
By default, in a HIDECAN plot, the points representing both
significant markers and DE genes are coloured according to their GWAS/DE
score. However, it is possible to colour the DE genes by their
log2(fold-change) value instead, by setting the
colour_genes_by_score argument to FALSE:
hidecan_plot(
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
colour_genes_by_score = FALSE
)
Genes with a negative log2(fold-change) will be represented with a shade of blue, and genes with a positive log2(fold-change) will be represented with a shade of red.
More than one QTL, GWAS, DE or candidate gene list
The hidecan_plot() function can take as an input lists
of data-frames for QTL mapping, GWAS and DE results or candidate genes.
This way, it is possible to visualise more than one QTL mapping, GWAS or
DE analyses at once, for example if investigating several traits at once
or comparing more than two treatment groups.
For this example, we’ll focus on chromosomes 7 and 8 (only for clarity of the plot):
library(dplyr)
library(purrr)
library(stringr)
## Retaining only markers and genes on chromosomes 7 and 8
x_small <- x |>
map(~ filter(.x, str_detect(chromosome, "(07|08)")))We’ll create a second data-frame of GWAS results by shuffling the marker scores in the example dataset:
## Creating a second GWAS result tibble by shuffling
## the marker scores from the original data
gwas_1 <- x_small[["GWAS"]]
gwas_2 <- gwas_1 |>
mutate(score = sample(score))We can pass both GWAS results data-frames to the
hidecan_plot() function as a list:
hidecan_plot(
gwas_list = list(gwas_1, gwas_2),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0
)
By default, the two GWAS tracks will be given unique y-axis labels, as can be seen above. It is possible to customise this by naming the elements in the input list:
hidecan_plot(
gwas_list = list("Trait 1" = gwas_1,
"Trait 2" = gwas_2),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0
)
If you want to represent different sets of QTL regions which would be coloured by track rather than score, see the example at the end of the “Controlling the aesthetics” section.
Defining chromosomes length
By default, the hidecan_plot() function calculates the
length of the different chromosomes based on the input data, by looking
at the maximum position of genes and markers on each chromosome.
However, it is also possible to pass on a tibble of chromosome length
(in bp) through the chrom_length argument.
library(tibble)
## Chromosomes length as recorded in Ensembl Plants
potato_chrom_length <- c(
ST4.03ch00 = 45813526,
ST4.03ch01 = 88663952,
ST4.03ch02 = 48614681,
ST4.03ch03 = 62190286,
ST4.03ch04 = 72208621,
ST4.03ch05 = 52070158,
ST4.03ch06 = 59532096,
ST4.03ch07 = 56760843,
ST4.03ch08 = 56938457,
ST4.03ch09 = 61540751,
ST4.03ch10 = 59756223,
ST4.03ch11 = 45475667,
ST4.03ch12 = 61165649
) |>
## turn a named vector into a tibble
enframe(name = "chromosome",
value = "length")
head(potato_chrom_length)
#> # A tibble: 6 × 2
#> chromosome length
#> <chr> <dbl>
#> 1 ST4.03ch00 45813526
#> 2 ST4.03ch01 88663952
#> 3 ST4.03ch02 48614681
#> 4 ST4.03ch03 62190286
#> 5 ST4.03ch04 72208621
#> 6 ST4.03ch05 52070158
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
chrom_length = potato_chrom_length
)
Note that in this case we can’t really see the difference with the computed chromosome length values.
Controlling the plot properties
The hidecan_plot() function offers several arguments to
control different aspects of the HIDECAN plot. For example, it is
possible to specify the number of rows or columns the plot should have,
through the n_rows and n_cols arguments. Note
that only one of these arguments will be considered (n_rows
takes precedence):
## Specifying the number of rows
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
n_rows = 3
)
## Specifying the number of columns
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.005),
log2fc_thr = 0,
n_cols = 3
)
In addition, it is possible to:
add a title and subtitle to the plot (
titleandsubtitlearguments);control the position of the legend (
legend_positionargument);control the size of the points (
point_sizeargument);control the size of the labels and padding around the text for the candidate genes labels (
label_sizeandlabel_paddingarguments).
Creating a Manhattan plot
It is possible to visualise GWAS results with a Manhattan plot
through the manhattan_plot() function. The function takes
as input a data-frame (or list of data-frames) of GWAS results, which
must follow the same rules as for plot_hidecan() function
(see this section of the
vignette). A horizontal line representing the significance threshold can
be added to the plot, by passing the threshold value to the
score_thr argument.
manhattan_plot(x[["GWAS"]], score_thr = 4)
As for the hidecan_plot() function, it is possible to
pass a list of GWAS results to the function, in order to draw several
Manhattan plots in one figure. The names of the list will be used to
identify the different plots:
manhattan_plot(list("Trait A" = x[["GWAS"]],
"Trait B" = x[["GWAS"]]),
score_thr = 4,
ncol = 1)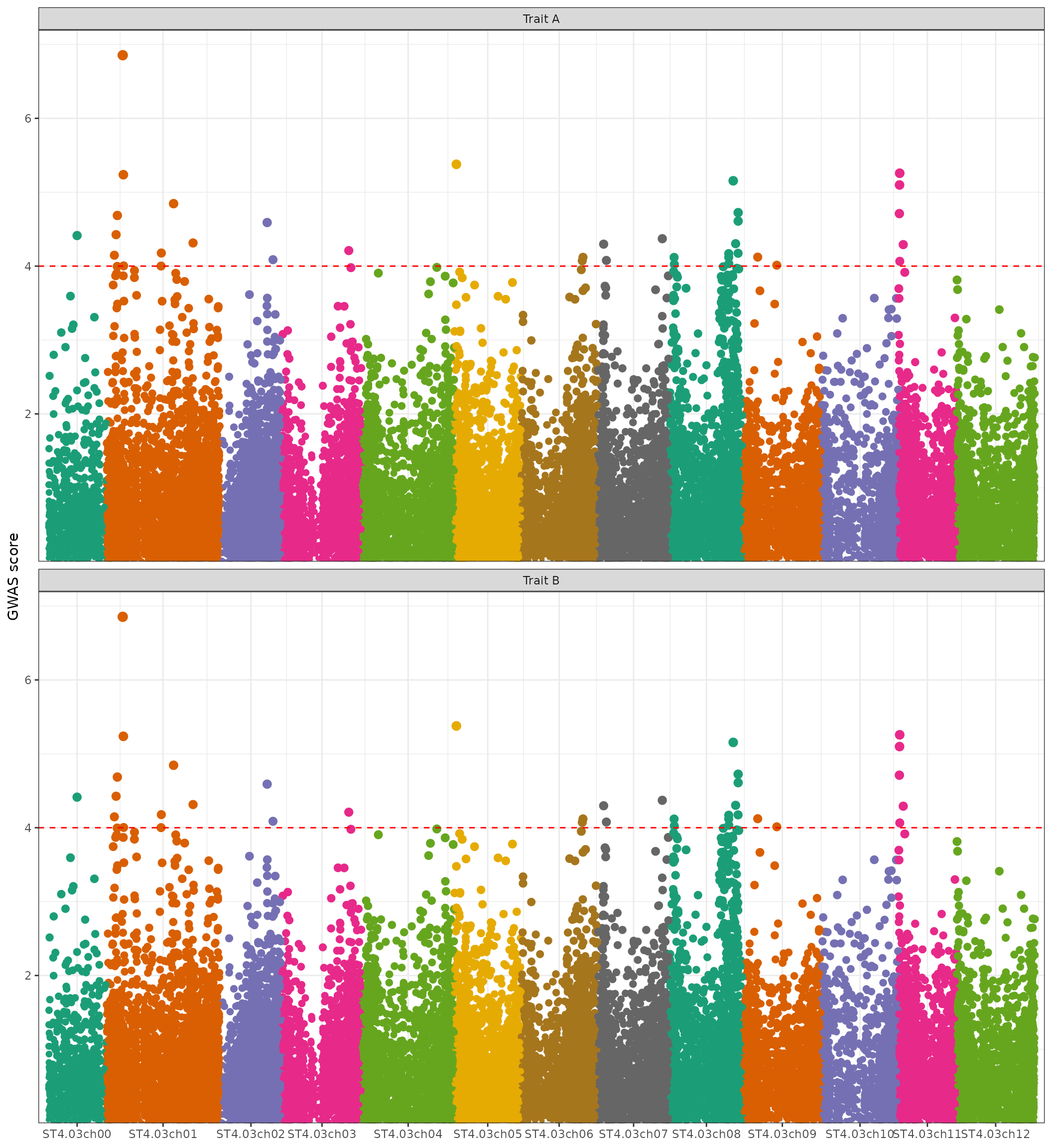
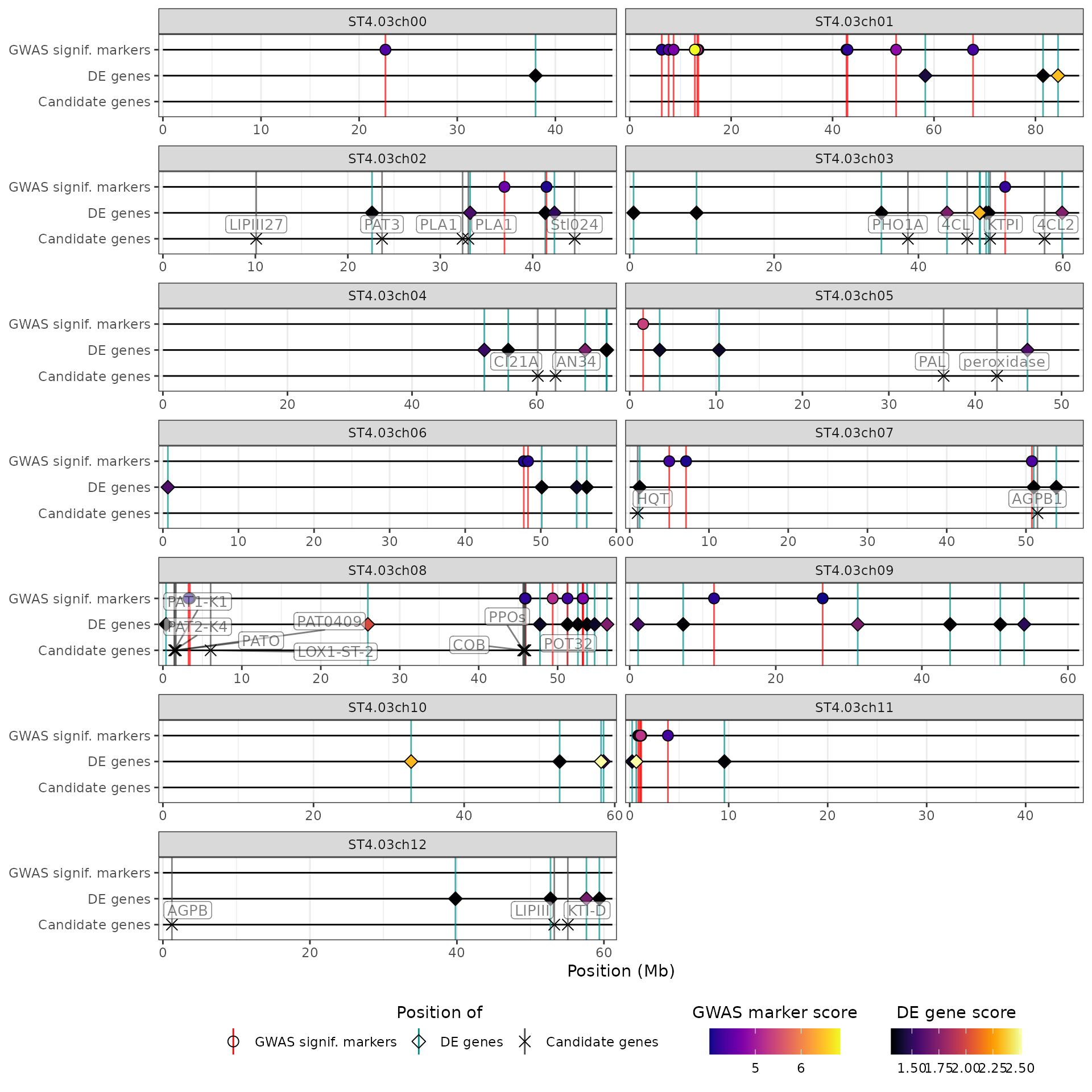
Controlling the aesthetics (colours, point shapes, labels) of the tracks
The default look of the different data types (QTL regions, GWAS
peaks, DE genes and candidate genes) in a HIDECAN plots is controlled by
the arguments returned by hidecan_aes(). More specifically,
the function controls:
whether each track is represented as a point (the default for GWAS, DE and candidate genes tracks) or as a rectangle spanning a genomic region (the default for QTL track),
the label of each data type on the x-axis (e.g. ‘GWAS peaks’ for GWAS results),
the colour of the vertical lines used to showcase the position of markers or genes, or of the vertical “shadow” used to showcase the position of genomic regions,
the shape of the points,
for genomic regions, the width of the box used to represent them,
whether the name of the regions/markers/genes are displayed (by default, will only show for candidate genes),
the colour palette used for the score or log2 fold-change of the points.
The default values used for these parameters have been chosen to
ensure that the resulting plot is easily understandable. However, it is
possible to change them. To do so, we’ll start by saving the defaults
returned by hidecan_aes():
default_aes <- hidecan_aes()
str(default_aes, max.level = 1)
#> List of 5
#> $ QTL_data_thr :List of 7
#> $ GWAS_data_thr :List of 7
#> $ DE_data_thr :List of 7
#> $ CAN_data_thr :List of 7
#> $ CUSTOM_data_thr:List of 7
default_aes[[1]]
#> $y_label
#> [1] "QTL regions"
#>
#> $show_as_rect
#> [1] TRUE
#>
#> $line_colour
#> [1] "grey80"
#>
#> $point_shape
#> [1] 24
#>
#> $show_name
#> [1] FALSE
#>
#> $fill_scale
#> <ScaleContinuous>
#> Range:
#> Limits: 0 -- 1
#>
#> $rect_width
#> [1] 0.5As we can see above, the function returns a list of the default
aesthetics to use for QTL mapping results (the QTL_data_thr
element), for GWAS results (the GWAS_data_thr element), for
DE results (DE_data_thr element), for candidate genes
(CAN_data_thr element), and for custom tracks
(CUSTOM_data_thr element - see the Adding custom tracks article for
more information). Each element is itself a list, containing the value
for each attribute mentioned above.
Let’s modify the label given to the GWAS peaks, and the colour palette used for DE score:
library(viridis)
default_aes$GWAS_data_thr$y_label <- "GWAS signif. markers"
default_aes$DE_data_thr$fill_scale <- scale_fill_viridis(
"DE gene score",
option = "inferno",
guide = ggplot2::guide_colourbar(
title.position = "top",
title.hjust = 0.5,
order = 4 # ensures this legend is shown after the one for GWAS scores
)
)We can use these modified values by passing this list to
hidecan_plot() through its custom_aes
argument:
hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
custom_aes = default_aes
)
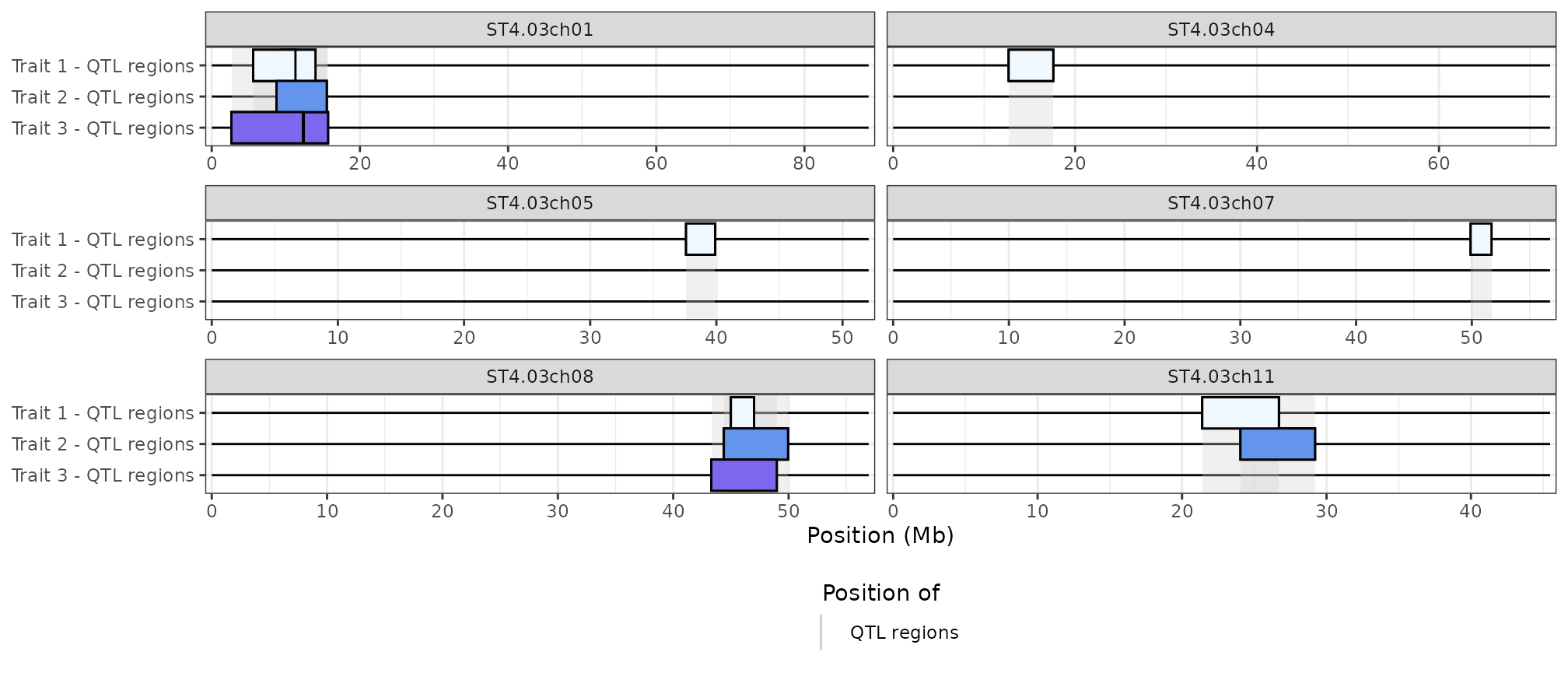
We can use this trick to represent different set of QTL regions, e.g. associated with different traits coloured by track rather than by their score. Let’s start by generating two other random set of QTL regions:
set.seed(356)
qtl_1 <- x[["QTL"]]
qtl_2 <- qtl_1 |>
slice_sample(n = 3) |>
mutate(
start = start + round(runif(3, min = -3, max = 3) * 1e6),
end = end + round(runif(3, min = -3, max = 3) * 1e6)
)
qtl_3 <- qtl_1 |>
slice_sample(n = 3) |>
mutate(
start = start + round(runif(3, min = -3, max = 3) * 1e6),
end = end + round(runif(3, min = -3, max = 3) * 1e6)
)The key is to give each set of QTL regions a score representing the colour we want to assign to them (here, we’ll use a different colour for each trait):
qtl_list <- list(
"Trait 1" = qtl_1 |> mutate(score = 1),
"Trait 2" = qtl_2 |> mutate(score = 2),
"Trait 3" = qtl_3 |> mutate(score = 3)
)We can then create a specific colour palette for each trait:
library(ggplot2)
new_aes <- hidecan_aes()
new_aes$QTL_data_thr$fill_scale <- scale_fill_gradientn(
colours = c("aliceblue", "cornflowerblue", "mediumslateblue"),
guide = "none"
)
hidecan_plot(
qtl_list = qtl_list,
score_thr_qtl = 0, ## to avoid removing QTLs based on score
chrom_length = potato_chrom_length,
remove_empty_chrom = TRUE,
custom_aes = new_aes
)
Viewport error
If you are working on RStudio, you may encounter the following error:
#> Error in grid.Call(C_convert, x, as.integer(whatfrom), as.integer(whatto), : Viewport has zero dimension(s)This is caused by the plotting window being too small. Try increasing
the size of the plotting window in the RStudio console. Alternatively,
you can save the plot into an R object, then use
ggplot2::ggsave() to save it into a file:
p <- hidecan_plot(
qtl_list = x[["QTL"]],
gwas_list = x[["GWAS"]],
de_list = x[["DE"]],
can_list = x[["CAN"]],
score_thr_qtl = -log10(0.0001),
score_thr_gwas = -log10(0.0001),
score_thr_de = -log10(0.05),
log2fc_thr = 0,
label_size = 2
)
ggplot2::ggsave("hidecan_plot.pdf", p, width = 10.5, height = 11)